2024年11月30日に開催された「GMO Developers Day 2024」において、GMOペイメントサービス株式会社の海老澤が登壇し、東京大学データサイエンスティスト養成講座との連携を通じたAI技術の活用事例を発表しました。
本記事では、そのセッション内容を書き起こし、不正検知や与信管理における最新の取り組みと成果、さらには新たに導入予定のAI与信モデルと今後の展望について詳しく紹介します。企業のデータ活用における実践的な知見と、AIがもたらす業務革新の可能性に迫ります。
自己紹介

GMOペイメントサービス株式会社
ビジネスインサイト部 データインテリジェンス課
海老澤 勇治
私は2023年1月に入社し、現在はビジネスインサイト部データインテリジェンス課に所属しております。主な業務内容としては、GMO後払いサービスや「アトカラ」の与信管理、不正検知、そして社内与信システムの与信ルール運用を担当しております。また、AIを活用した不正検知や類似取引検索、与信ルール作成の自動化など、与信業務の高度化・効率化にも積極的に取り組んでおります。
東京大学データサイエンスティスト養成講座(DSS)との連携

まず、今回のセッションのテーマである東京大学データサイエンスティスト養成講座(以下、DSS)についてご紹介いたします。DSSは、東京大学大学院情報理工学系研究科が主体となって運営するデータサイエンスに特化した教育プログラムです。このプログラムは、基礎、応用、実践の3段階に分かれた講座で構成されており、その中核講義として、学生がビジネス現場から提供された実データを用いて実際に分析を行うという特徴があります。
グループ会社のGMOペイメントゲートウェイが、2018年4月からこのDSSとの連携を開始し、以降、GMOペイメントサービスが提供する「GMO後払い」の決済データの分析に取り組んでいただいています。
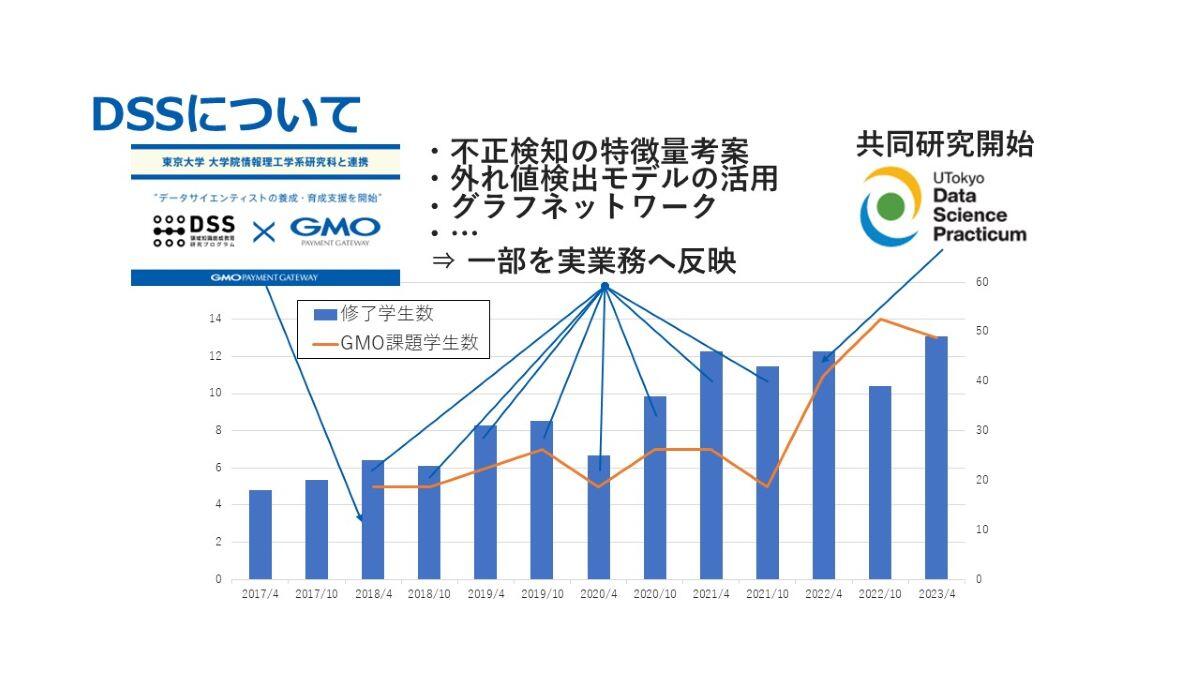
このグラフは、DSSのこれまでの取り組みを時系列で表したものです。青線はDSS全体の修了学生数を、オレンジ線は課題に取り組んでいただいた学生数を示しています。
ご覧のとおり、半期ごとに約5名から10名程度の学生が参加しており、これまでに約100名の学生が弊社の課題に取り組んでくださいました。その中では、不正検知の特徴量の考案や、外れ値検出モデルの活用、グラフネットワークといった多様なアイディアが発揮され、一部は実務にも反映されています。
2022年4月からは共同研究も開始され、より高度なデータ分析にも取り組んでいただいております。
DSSでの具体的な取り組みと成果

次のページ以降では、DSSの具体的な成果についてご紹介しますが、まずは全体の概要についてご説明いたします。DSSでは主に2つのテーマに取り組んでいます。1つ目は、決済データに含まれる不正取引の検出、いわゆる「不正検知」です。2つ目は、未払いとなる取引の予測であり、こちらは不正取引に限らず、どのような取引が未払いになるのかを分析する、より高度な分析となっています。
主な成果として、まず新たな不正パターンの検出方法の考案が挙げられます。これは、これまで行われていなかった不正取引の掘り起こしプロセスを定期運用するきっかけとなる重要な成果です。
次に、独自のAIモデル構築や特徴量の考案も進められました。この取り組みでは、学生たちの斬新な発想を活かし、不正検知精度を向上させる特徴やモデルが考案されました。
最後に、未払いに至るケースを予測するための「支払予測モデル」も考案されました。このモデルは、未払いリスクを事前に把握し、リスク管理を高度化する上で大きく貢献しています。
具体的な成果
DSSでの主な取り組み① - 実業務での活用例
ここからは、DSSの具体的な取り組みと成果について、3つに分けてご紹介します。
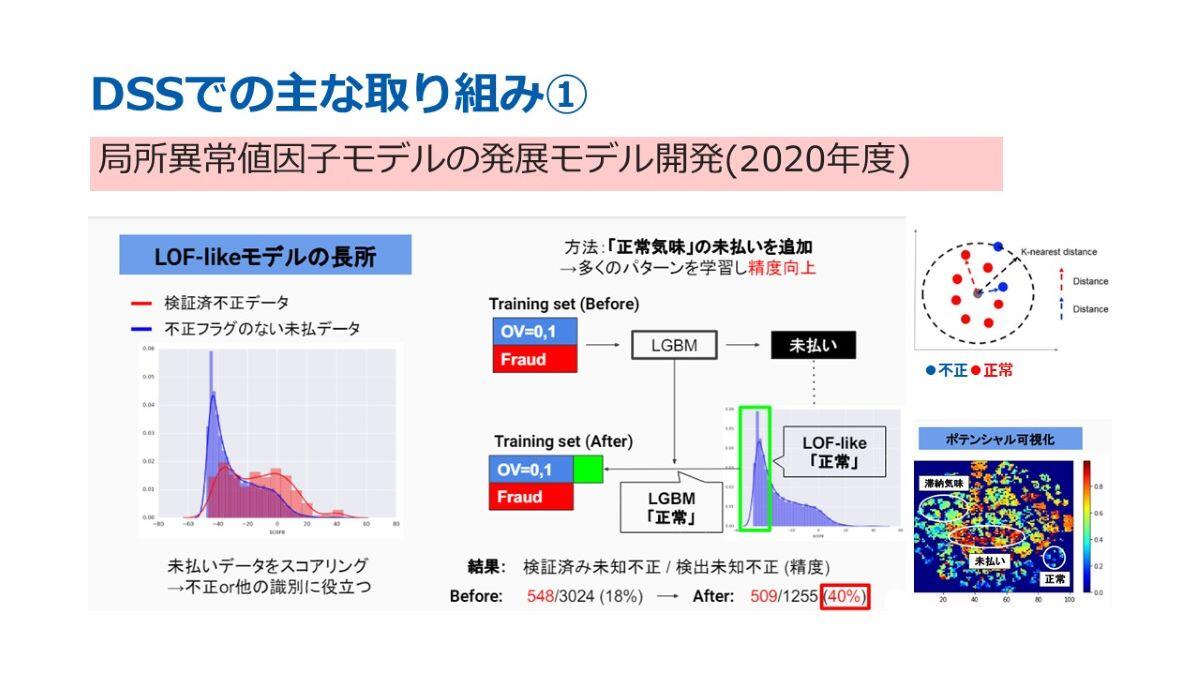
まず1つ目は「局所異常値因子モデル(以下LOF)の発展的モデルの開発」についてです。局所異常値因子モデルは、Local Outlier Factor(通称LOF)と呼ばれるもので、一般的に広く異常値検知に用いられるモデルです。
今回の取り組みでは、学生の方々がこのLOFモデルを基に、単なる異常値検出ではなく、「正常寄り」か「不正寄り」かを、ある程度定量的に評価できるように改良を加えました。この改良モデルを実際に適用した結果が左側のグラフに示されています。このグラフでは、青色が正常取引、赤色が不正取引を表していまして、青色のグラフは左側に、赤色のグラフは右側に寄っており、このモデルが取引を「正常寄り」または「不正寄り」として適切に分類していることが分かります。
この改良モデルでは、スコアの値が小さいほど「正常寄り」、大きいほど「不正寄り」と評価されるよう設計されています。モデルの適用結果からも、その仕組みが実際に機能していることが確認できました。
さらに、このLOFライクモデルはさまざまなシーンで活用できます。その一例が未払い取引への適用です。未払い取引の場合、支払いが完了するまで「正常」か「不正」かの判定が非常に難しいのですが、このモデルを適用することで、取引が「正常寄り」か「不正寄り」かを、事前にある程度判別することが可能になりました。
また、LOFライクモデルを用いて「正常寄り」と判定された未払い取引を正常取引のトレーニングデータセットに追加することで、不正検知モデルの精度を向上させることもできました。
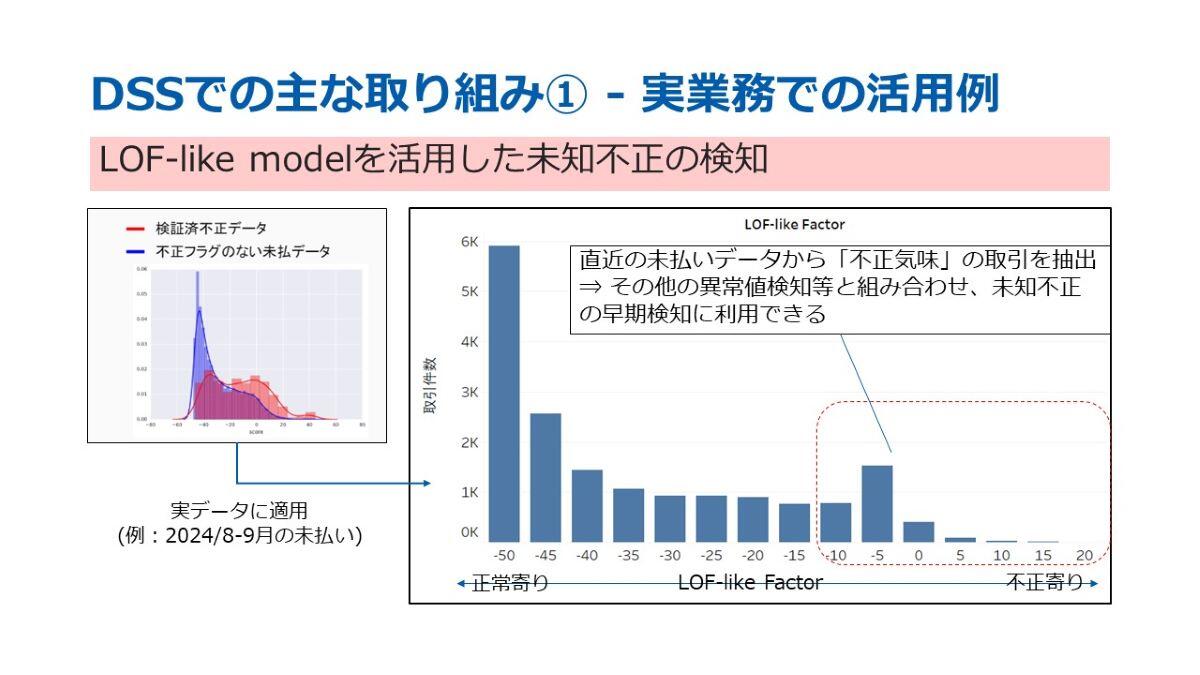
また、このLOFライクモデルを実務に適用した具体例をご紹介します。こちらは先ほどと同様のLOFライクモデルを、2024年8月から9月にかけて弊社の未払い実データに適用したものです。繰り返しになりますが、左側が「正常寄り」、右側が「不正寄り」と判定された取引です。
この適用結果では、未払いデータが多く含まれている中で、右側(不正)に寄っているデータがいくつか確認されます。未払いデータの場合、不正かどうかの判定は非常に難しく、またその件数も多いのが実情です。しかし、このLOFライクモデルを活用することで、不正の可能性が高いデータを効率的に絞り込むことが可能となりました。
DSSでの主な取り組み②
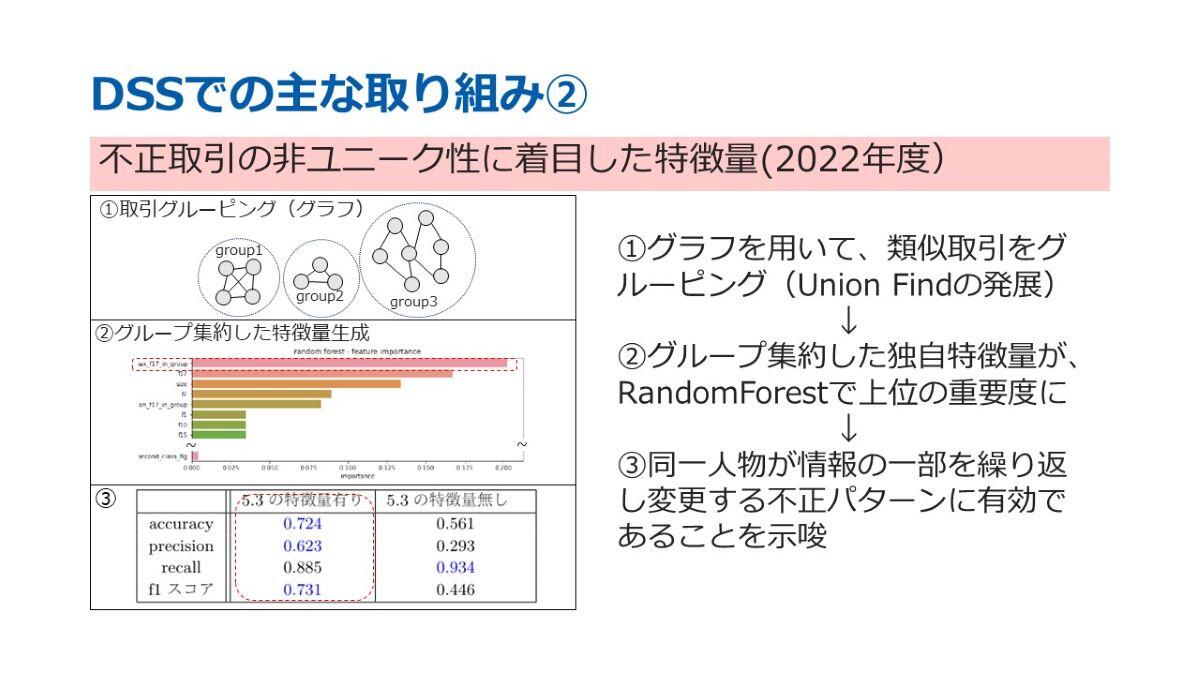
続いて、2つ目の成果についてご紹介いたします。こちらは、不正取引の「非ユニーク性」に着目した特徴量についての研究です。「非ユニーク性」とは、不正取引に特有の異常なまとまりを指す概念です。
このまとまりに着目し、検知の精度を向上させることができないかというアイディアです。
この取り組みは、以下のような3つのステップで進められました。
まず第1段階として、取引をグルーピングしました。この際、一般的に使用される「Union-Find」というアルゴリズムをベースに発展させ、現実的な処理時間内で類似取引をグルーピングできるようにしました。
次に、第2段階では、グループ化したデータから特徴量を生成しました。この特徴量を用いてRandom Forestアルゴリズムで学習を行いました。その結果、グループ化したデータから抽出された特徴量が、ランダムフォレストの重要な特徴量として上位に位置づけられることが確認されました。
最後の第3段階では、この特徴量を活用したモデルと特徴量を用いないモデルを比較しました。その結果、特徴量を用いたモデルの方が精度が向上することが明らかになりました。
DSSでの主な取り組み③

3つ目の成果として、「支払い予測モデル」についてご紹介します。このモデルはこれまでのテーマとは少し異なり、不正取引に限定されず、一般的にどのような取引が未払いに陥るのかを分析するためのものです。
ここで使用されるデータのイメージは、上の表に示されています。これらの取引は、ある時点で支払いが完了するものもあれば、未払いとなるものも存在します。このような支払の状況を「ステージ」として分類しています。
たとえば、取引が「ステージ0」にある場合、それは期限内にきちんと支払いが行われたことを意味します。このケースは、表の左下に記載されている「期限内入金」として分類されます。一方で、「ステージ5」の取引は、最も下位のステージに位置し、長期未払いとして扱われるものです。また、「ステージ1」に該当する取引は、期限内ではないものの、ある程度のタイミングで支払いが完了したケースです。
未払いに陥る典型的なケースとしては、初めのうちはきちんと支払いが行われていたものの、次第にステージが上がり、最終的に支払いが行われなくなってしまう、という流れが挙げられます。一方で、最初はやや支払が遅れ気味だったユーザーが、何らかの要因によって支払状況が改善していくケースも確認されています。
このような各ユーザーの支払い履歴を時系列データとしてモデルに学習させることで、注文の段階でその取引の支払までの期間を予測する問題に取り組みました。
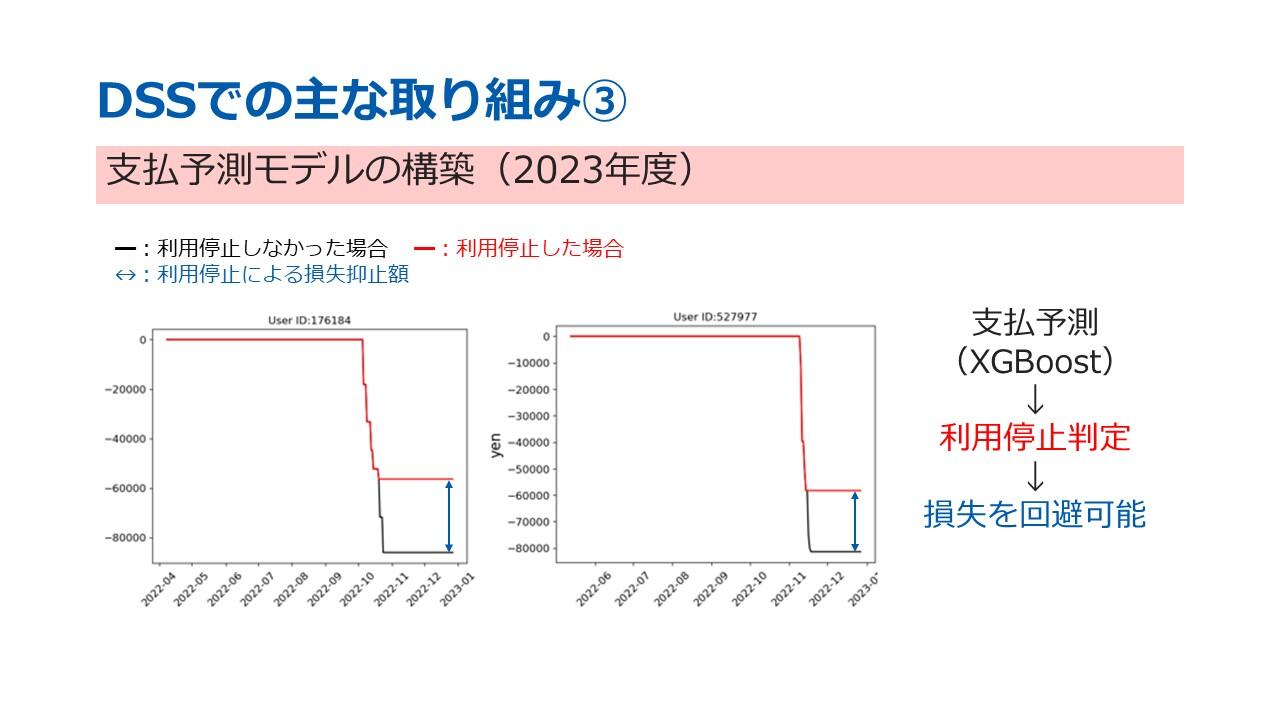
XGBoostにユーザーの支払に基づいた特徴量を学習させることで、取引の支払確率を算出することが可能となりました。たとえば、「この取引は90%の確率で支払われない」という結果が得られた場合、その時点で該当取引の利用を停止するという判断ができるようになります。
実際に、このモデルを適用した結果が左側のグラフに示されています。黒線は実際の決済履歴を表しており、途中でマイナスの値となっているのは、支払いが行われず損失が発生したことを意味します。一方、赤線はモデルの利用停止判定を適用した場合の決済を示しており、損失がすべて発生する前の段階で利用停止に成功しています。さらに、青線は損失の抑止額を示しており、このモデルの適用によってどの程度の損失が回避されたかを明確に示しています。
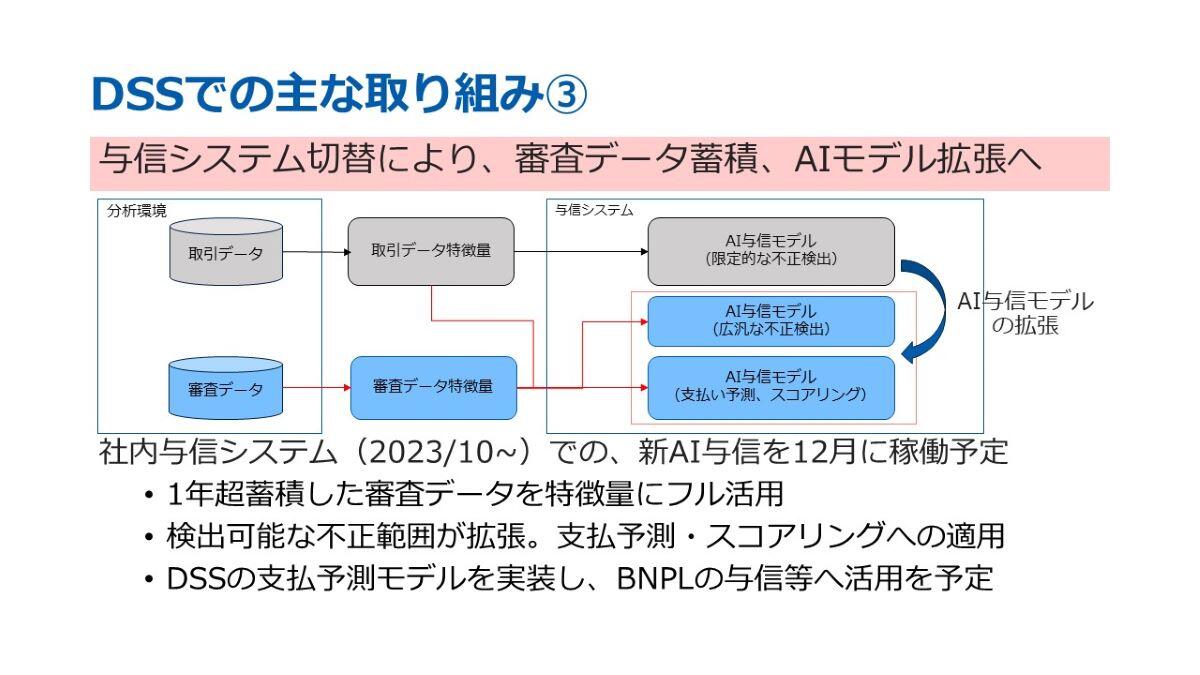
ここでは、これまでご説明してきたAIモデルを弊社がどのように活用しているかについてご紹介いたします。弊社では、与信システムにおいて、新たなAI与信エンジンを稼働させる予定です。このAI与信では、1年以上にわたり蓄積してきた新しいデータを新たな特徴量として活用することが可能となります。
これにより、従来のAI与信モデルを刷新し、より広汎な不正検知や、支払い予測モデル、さらにスコアリングといった、より新しいAI与信モデルの作成が期待されます。
新たなAI与信モデルの導入と今後の展望

最後に、AI活用の展望について述べ、このセッションのまとめとさせていただきます。
まず1点目として、12月に新たなAI与信エンジンを本格稼働させる予定です。このAI与信エンジンでは、不正検知モデルやDSSの支払い予測モデルの搭載を進めていきます。
また、AI与信と並行して、ルールベースの与信も引き続き活用していきますが、不正検知からルール作成までの一連のプロセスの自動化に取り組んでいきます。この自動化プロセスでは、埋め込み表現やグラフを活用した、不正の検索精度向上も目指しています。
さらに、AI活用の領域を広げ、大規模言語モデル(LLM)を活用した業務効率化にも注力します。具体的には、カスタマーサービス部門でのメール作成業務や電話対応業務にLLMを導入し、これらの業務の効率化と品質向上を支援していく計画です。
※本コンテンツ内容の著作権は、GMOペイメントゲートウェイ株式会社に属します。