2024年11月29日(金)‐30日(土)に開催された「GMO Developers Day 2024」で、GMOペイメントゲートウェイ株式会社の長沢が登壇し、Apache SparkとDatabricksを活用した大規模データ処理改善の取り組みについて発表しました。本記事では、Spark導入の背景やDatabricksの活用法、具体的な成果と課題、さらには今後の展望について詳しく解説します。急増するデータ処理量に対応するための技術的アプローチやその実用性を、実務に基づいた視点で紹介します。
自己紹介

GMOペイメントゲートウェイ株式会社
システム本部ユーティリティ決済グループ
長沢翔太
2017年に新卒で入社し、 これまでインフラ向け決済サービスや送金サービスの開発・運用に携わってきました。 現在は、クレジットカード基幹システムの開発・運用を担当しています。
カード決済売上洗替作成システムの概要
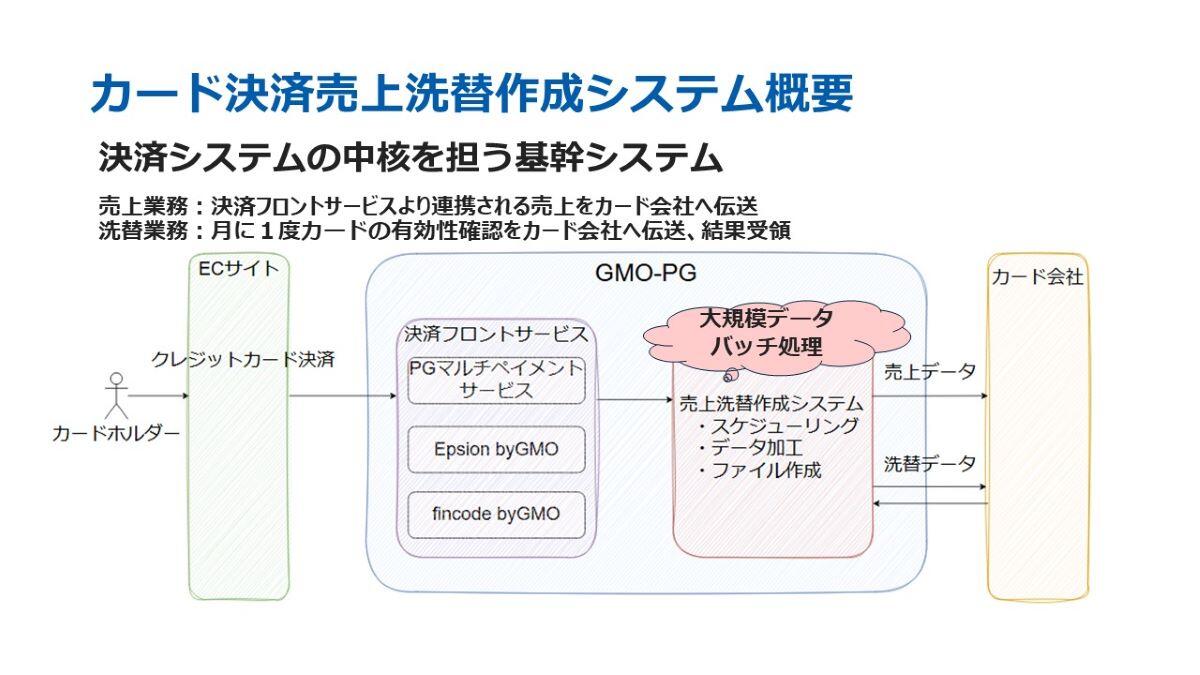
当社の基幹システムである「カード決済売上洗替作成システム」は、決済業務において非常に重要な役割を担っています。このシステムは、主に売上業務と洗替業務の2つの機能を持っています。
売上業務では、決済フロントサービスから受け取った売上データを加工し、カード会社に伝送します。一方、洗替業務では、月に一度、カードの有効性を確認し、カード番号や有効期限が変更されたものを更新する作業を行っています。この洗替業務は、継続課金における役割を果たします。
これらの業務はどちらも、カード決済に欠かせないものであり、大規模データを扱うバッチ処理によって運用されています。今回のパフォーマンス改善検証では、この「洗替」に焦点を当てて実施いたしました。
課題
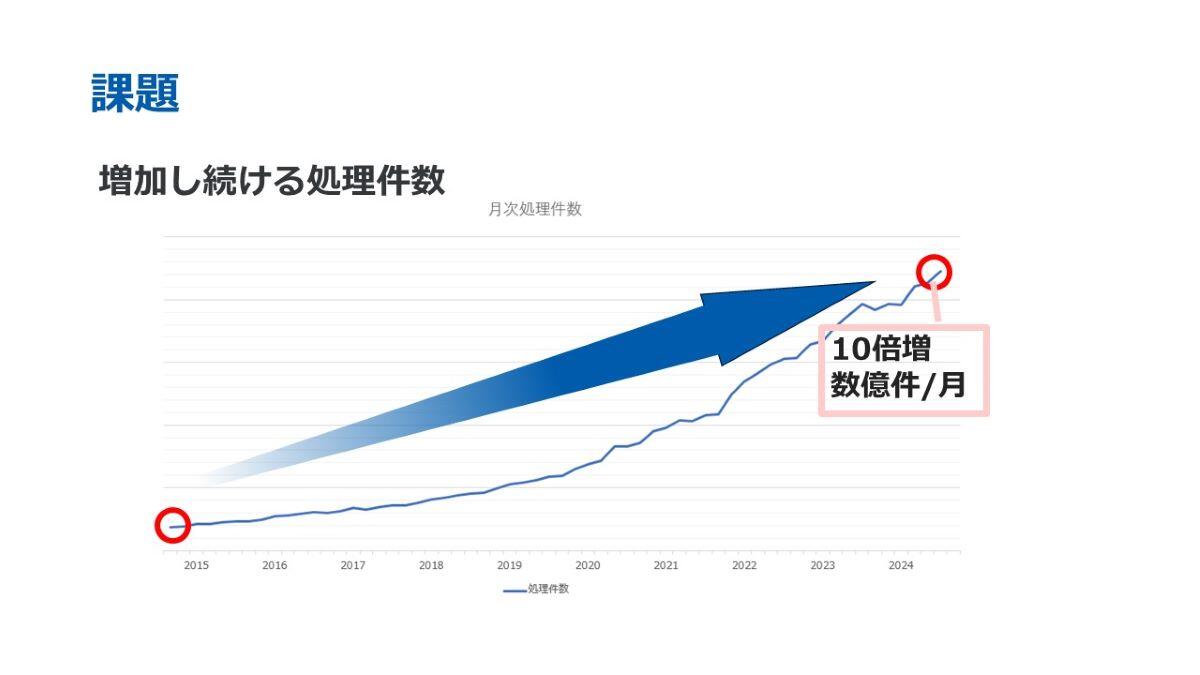
こちらは、洗替業務における月次処理件数の推移を示したものです。10年前と比較すると処理件数は約10倍に増加しており、現時点では月に数億件を処理しております。
洗替処理は、月に1度に集中して実施される業務です。そのため、処理件数が増加するに伴い、処理時間が長くなり、システム負荷が大きくなるという課題がございました。
パフォーマンス改善のアプローチ
Apache Sparkの導入
そこで、今回Apache Sparkを活用したパフォーマンス改善に取り組みました。Apache Sparkは、並列分散処理を行うためのフレームワークです。並列分散処理とは、複数のサーバーを利用して同時に処理を実行する仕組みであり、クラウドサービスとの相性が良く、リソースを容易に増強できるという強みを持っています。
一方で、並列分散処理にはデメリットもあります。自前で設計・実装しようとすると、スレッド管理や同期処理などの設計が非常に複雑になる点です。しかし、Apache Sparkを利用することで、これらのデメリットが大幅に軽減され、簡単に設計や実装を行うことが可能となります。
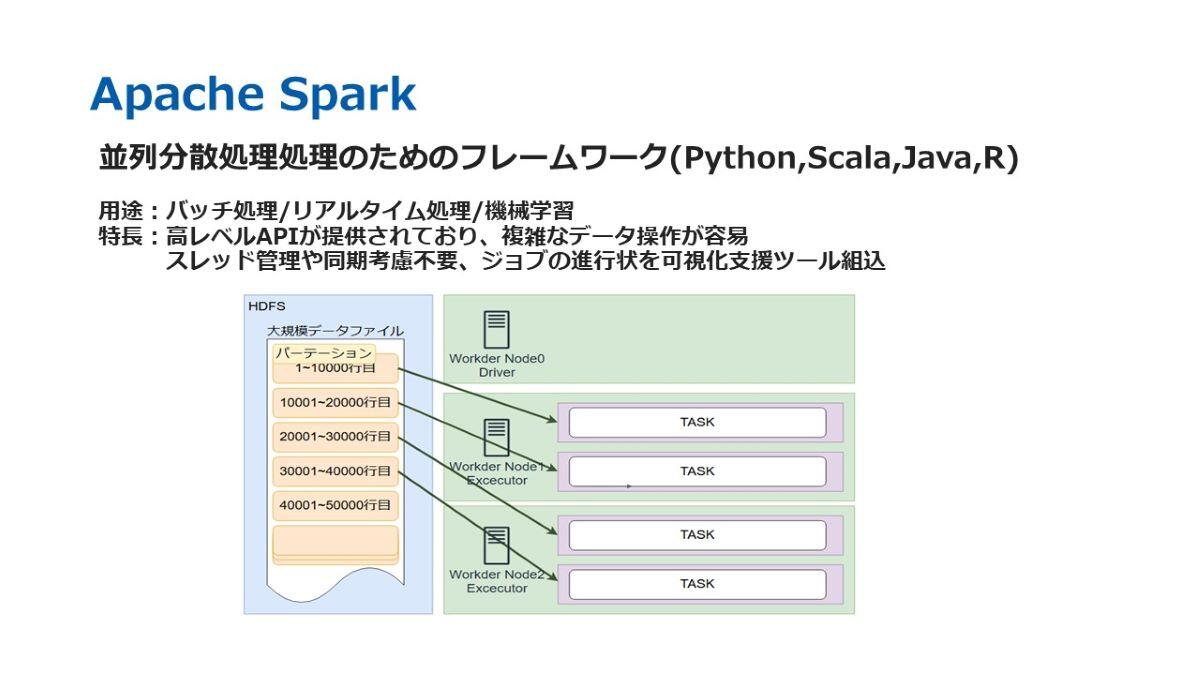
ここで、Apache Sparkを利用した際のデータの流れについて簡単にご説明します。左側に示されている青色の「HDFS」と記載された領域がストレージ部分に該当します。ストレージとしては、データベースやファイルストレージを利用することができます。右上にある「ドライバー」と呼ばれる領域は、タスクの計画や配分を行う役割を担っています。そして、下部の緑色で示された「エグゼキューター」の部分が、実際に並列で分散処理を実行する箇所です。
さらに、図中の紫色の部分はコアを表しており、ここでは1エグゼキューターあたり2コアを持つサーバーが2台存在していることを示しています。処理の流れとしては、HDFSに置かれた大規模データファイルが、まず「パーテーション」という単位に分割されます。分割されたパーテーションは、それぞれのエグゼキューターに配布され、各エグゼキューターが並列でタスクを実行します。未割り当てのパーテーションについては、処理が完了したエグゼキューターパーテーションスに順次割り振られ、処理が進行していきます。
クラウドサービスの活用
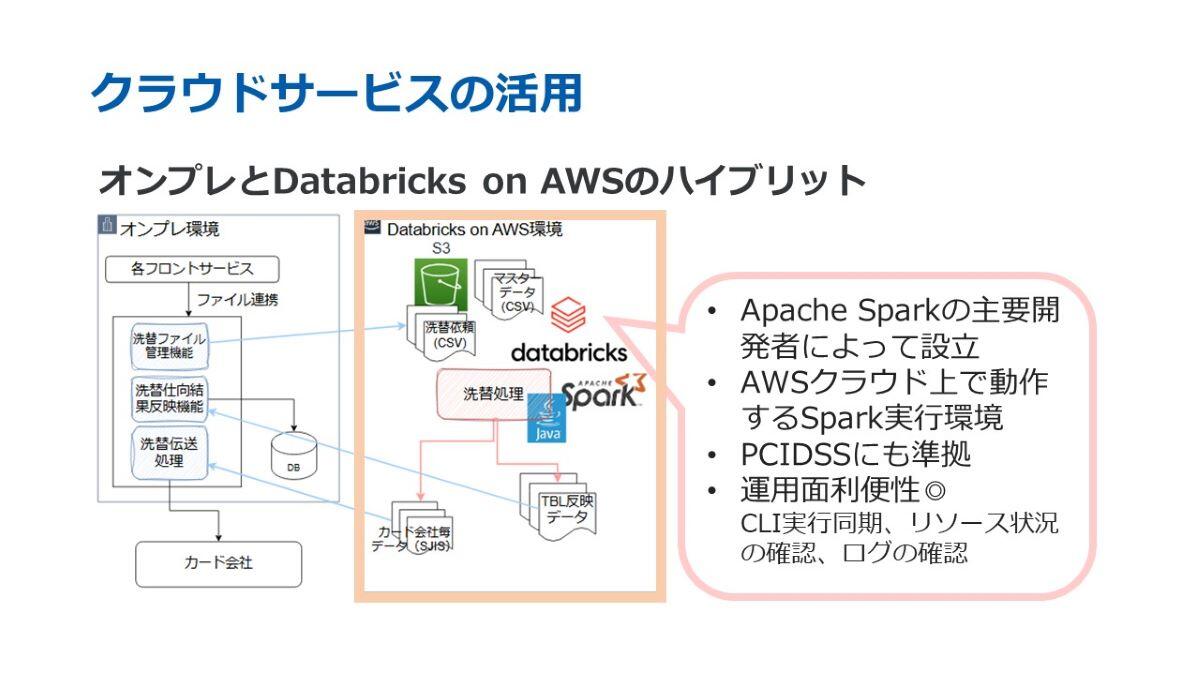
先ほど、クラウドサービスとの相性が良い点についてお話しいたしましたが、今回、私たちは「Databricks on AWS」を利用しております。このDatabricksは、Databricks社が提供するAWSクラウド上で動作するSpark実行環境です。
いくつかのクラウドサービスを比較検討した結果、CLIの実行が同期的に行える点や、リソース状況やログの確認が容易である点から、運用面での利便性が高いことが評価され、Databricksを採用しました。この環境を利用することで、AWS上で洗替処理を並列分散で実行しております。
また、その他の機能については、フロントサービスからファイルを連携受ける部分や、カード会社へのデータ伝送部分について、既存のオンプレミス環境を引き続き使用する形をとっています。このように、クラウド環境とオンプレミス環境を組み合わせたハイブリッドな構成を採用しております。
レガシーシステムとSparkシステムの比較
既存のレガシーバッチ
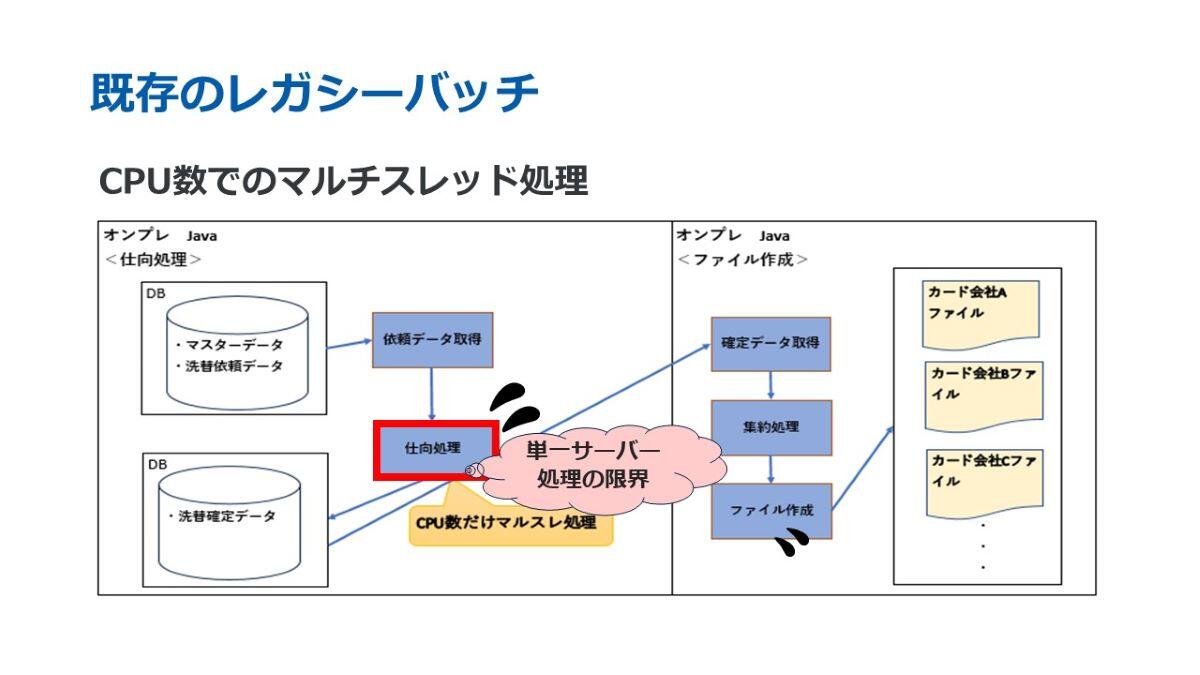
続きまして、洗替処理における既存のレガシーバッチと新たなSparkバッチについてご説明いたします。レガシーバッチは、オンプレミス環境で動作するJavaアプリケーションとして構築されています。
洗替処理は2つのステップに分かれています。1つ目は「仕向け処理」、2つ目は「ファイル作成」です。「仕向け処理」は、データをどのカード会社に伝送するかを判断するプロセスであり、現在、CPU数を用いたマルチスレッド処理で実行しています。しかし、複雑な業務ロジックを含むため、非常に多くの処理時間を要しています。
さらに、この仕向け処理は洗替だけではなく売上においても利用される共通のロジックとして機能しています。そのため、このロジックは本サービスにおいて非常に重要な役割を担っているといえます。
JavaによるSparkバッチ
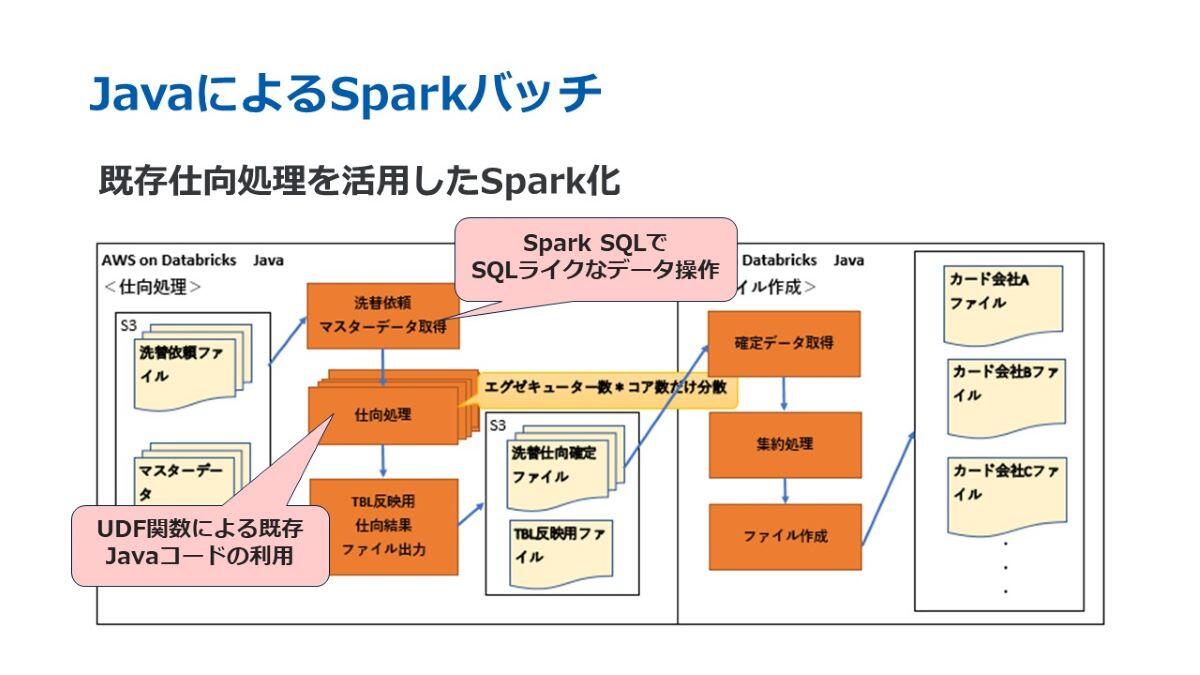
続きまして、Sparkバッチについてご説明いたします。こちらは、Databricks on AWSで動作するJavaアプリケーションであり、複数のサーバーで並列分散処理を行う仕組みを備えています。
Sparkには、バッチ処理を効率的に行うための多くの機能が備わっています。その中で特に重要なのが「Spark SQL」です。これは、大規模データを効率的に扱うためのAPIであり、データが分散されているにもかかわらず、分散環境を意識することなく柔軟かつ簡単にSQLライクな形式でデータ操作を可能にします。
また、先ほど「仕向け処理」が売上業務と共通で利用されているロジックであると説明しましたが、今回のSpark化の対象は洗替のみとなっています。ただし、Sparkには「UDF関数(ユーザー定義関数)」という機能があり、これはユーザーが定義した独自の関数をデータ列に適用することが可能です。このUDF関数を活用することで、既存の仕向けロジックをそのまま利用しつつ、Apache Spark側でこれを登録・呼び出し可能な形にしました。
この仕組みにより、売上処理を担うレガシーバッチと洗替処理を担うSparkバッチの双方で、同じロジックを共通で使用することができ、コードを二重で管理する必要がなくなりました。その結果、簡潔かつ効率的な実装が可能となりました。
検証結果
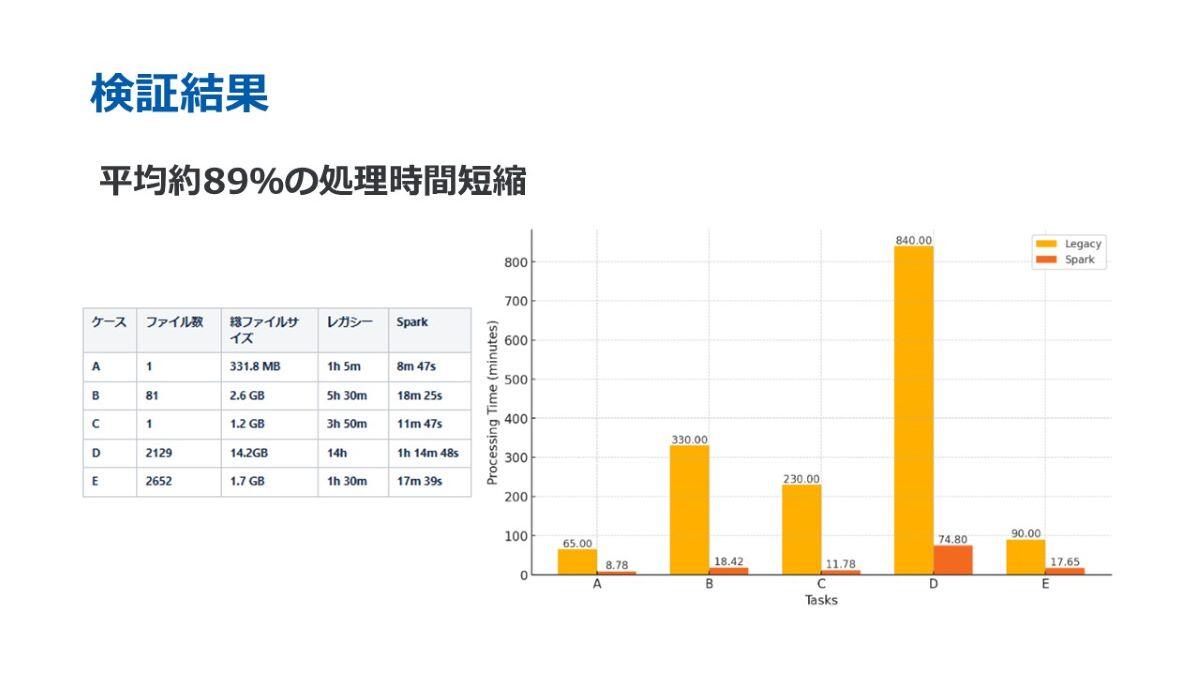
こちらは、レガシーバッチとSparkバッチで洗替処理を実行した際の処理時間を比較した結果になります。平均で約89%の処理時間短縮が達成されました。具体的には、従来14時間かかっていた処理が、1時間14分ほどで完了するようになりました。
なお、この結果は現状の設定での比較であり、インスタンスの数やタイプのチューニングによって、さらに改善の余地があると考えております。
良かった点と課題

Apache Sparkを利用して得られた良かった点と苦労した点についてお話しします。
まず、良かった点についてです。先ほどご紹介したように、Spark SQLやUDFなど、データ操作に便利なAPIや関数が非常に充実している点が挙げられます。これにより、データ処理の高速化が実際に実現できたことは非常に大きな成果でした。また、今後処理件数が増加した場合でも、Databricksを利用しているため、リソースを拡張することで対応可能な環境が整備できた点も良かったと感じています。
次に、苦労した点についてです。一つ目は、従来のJavaとの設計思想の違いへの対応です。例えば、Javaでは反復処理を利用して列操作を行うことが一般的ですが、Apache Sparkでは宣言的に記述するだけで全体に一括適用が行われます。この点に関して、初めは考え方の違いに戸惑いを感じる部分がありました。
また、Javaコードは通常、上から順に処理が実行されますが、Apache Sparkでは遅延評価が採用されています。そのため、アクション処理が呼び出されるまで、前段で記述した変換処理やフィルタ処理は実行されません。そして、新しいアクション処理を呼び出すたびに、最初から計算が再実行されます。そのため、重たい変換処理を行った後に何度も参照や再利用を繰り返す場合、処理が遅くなるケースがありました。
ただし、この問題に対してはキャッシュ機能が用意されており、この機能を利用することで同じ計算を省き、効率的にデータ操作を行うことが可能となりました。このように、従来のJavaとは特徴や考え方が異なる点が多くありましたが、これらを理解した上で実装を進めることで、Apache Sparkは大規模データを扱うための非常に強力なツールであると実感することができました。
今後の展望
今回の検証を通じて、Apache SparkとDatabricksを活用することで、大規模データの処理における有用性を確認することができました。今後は、実運用に向けた取り組みを進めていきたいと考えております。
具体的には、ログ監視やオートスケーリングといった運用面での検証を引き続き行い、将来的には売上処理への適用やデータ分析への活用など、利用範囲をさらに広げていきたいと考えています。
以上で、私の発表を終了いたします。本日はご清聴いただき、誠にありがとうございました。
※本コンテンツ内容の著作権は、GMOペイメントゲートウェイ株式会社に属します。